Pagination and Scroll Restoration with Turbolinks
This solution has issues we try to fix in part two. Still a useful read for context, though.
We’ve been hearing for a while now that HEY would (and did) double down on the frontend architecture Rails and Basecamp are known for – server-rendered-“HTML-over-the-wire”, sprinkles of JavaScript instead of SPA frameworks, no JSON APIs, Turbolinks – something quite against the grain of “modern” web development.
So shortly after HEY started handing out invitations, JavaScript-Twitter took to…well, Twitter…to lend their critiques. Here’s one that stuck with me:

The “it” here is restoring scroll position on a paginated, infinite-scrolling list of unread emails.
Rich didn’t just say this will be easier in your SPA-framework-of-choice, he said it’s “borderline impossible” without them. Impossible is a bold claim.
Let’s look at how we might do it.
How to build HEY in 15 minutes with Ruby on Rails
-
First, let Rails write (almost) all the code:
$ rails new scratchpad $ rails generate scaffold Email subject:string message:string -
That will have generated a
test/fixtures/emails.ymlfile, change its contents to this:<% 100.times do |i| %> email_<%= i %>: subject: 'Subject #<%= i %>' message: 'Message #<%= i %>' <% end %> -
Run
rails db:fixtures:loadto put some (fake) emails in your inbox. -
Run
rails server.
You have an inbox! Unfortunately, it loads all one hundred emails. We’ll fix that, but first lets fix restoring our scroll on our inbox.
Restoring scroll
Right now, if you scroll down in your list of emails, click “show”, and then click “back” you’re taken to the top of your inbox. Like this:
If we just use the back button, Turbolinks will serve a cached page and restore your scroll automagically 🔮 For links in our app, we have to restore the scroll. To do so, we have to 1) capture the scrollbar’s position before we leave the page and 2) restore it when we come back to the page. Using Turbolinks, we can use the turbolinks:before-visit to fire an event just before we leave a page.
That’s a bit of an over simplification. turbolinks:before-visit is fired just before we leave the page if we’re using Turbolinks to to travel to the next page. It is possible for you to have links in your application that are purposefully not using Turbolinks, and in that case you’ll have to hook into those with a regular click event. But once hooked in, the strategy is the same.
Similarly, Turbolinks gives us a turbolinks:render event which fires after Turbolinks has rendered the new page. Using these we have a place to capture the scrollbar’s position and restore it.
Capturing
Turbolinks.savedScrolls = {}
document.addEventListener("turbolinks:before-visit", function(event) {
if (document.querySelector("body[data-preserve-scroll=true]")) {
Turbolinks.savedScrolls = {
[window.location.href]: {
document: document.documentElement.scrollTop,
body: document.body.scrollTop
}
}
}
});
Turbolinks.savedScrolls is an object that we add to the global Turbolinks object. That non-TypeScript JavaScript is so damn flexible! Turbolinks.savedScrolls is a hash of saved scroll positions per page that looks like:
{ [url]: { document: position, body: position } }
We capture both because depending on your styling of html and body, you have to.
Also, this code lets you opt-in to this functionality on a page-by-page basis. That’s what the if (document.querySelector("body[data-preserve-scroll=true]")) does. If you don’t add that data attribute to your body tag, we won’t bother preserving the scroll location.
Restoring
document.addEventListener("turbolinks:render", function(event) {
const savedScroll = Turbolinks.savedScrolls[window.location.href]
if (!savedScroll) { return; }
delete(Turbolinks.savedScrolls[window.location.href])
if (savedScroll.document != null) {
if (savedScroll.document < document.documentElement.scrollHeight) {
document.documentElement.scrollTop = savedScroll.document
}
}
if (savedScroll.document != null) {
if (savedScroll.body < document.body.scrollHeight) {
document.body.scrollTop = savedScroll.body
}
}
});
Checks if we have a savedScroll for this page; if so, grabs it, deletes it from our hash, and sets the appropriate scrollTops.
If we weren’t paginating anything, that’s all it would take!
But we are.
Pagination
To mimic Hey (and countless other things), we want to implement an infinite-scroll style of pagination. Meaning, instead of clicking a “next” button and navigating to a whole new page of results, we will fetch and display the next page in the background when the user reaches the bottom of the screen.
For example:
The tricky part about infinite scrolling is there’s no page param in the URL, as opposed to something like https://news.ycombinator.com/news?p=2, where the p in the URL tells the server what page to fetch. So it’s on us to keep track of how many pages of emails you should see in your inbox when you navigate back to /emails.
There’s three different pagination cases we need to handle:
-
The basic pagination case of clicking the “Load More” button where we just fetch the next page of results.
-
The case where you’ve clicked “Load More” so you have two (or three or four or however many) pages loaded, you click into an email, then come back to your inbox, and we want to remember that you just had two pages loaded.
-
When you do really intend to start over at page one. For us, that’s gonna be on a full page refresh.
Basic pagination with infinite scroll “load more” button
#1 and #2 come fairly easily with any pagination library. We’ll use pagy. First, we adjust our index action like so:
class EmailsController < ApplicationController
def index
@pagy, @emails = pagy(Email.all)
end
end
By default, pagy expects params[:page] to tell it what page of emails to load, and if it’s missing to just load the first.
Next, we’ll create a partial for rendering a single email as a row in a table:
<!-- app/views/emails/_email.html.erb -->
<tr>
<td><%= email.subject %></td>
<td><%= email.message %></td>
<td><%= link_to 'Show', email %></td>
<td><%= link_to 'Edit', edit_email_path(email) %></td>
<td><%= link_to 'Destroy', email, method: :delete, data: { confirm: 'Are you sure?' } %></td>
</tr>
Now, we’ll use that partial in our inbox and add our “Load More” button:
<!-- app/views/emails/index.html.erb -->
<h1>Emails</h1>
<table>
<thead>
<tr>
<th>Subject</th>
<th>Message</th>
<th colspan="3"></th>
</tr>
</thead>
<tbody>
<%= render @emails %>
</tbody>
</table>
<br>
<% if @pagy.next %>
<%= form_with url: emails_path, method: :get do |f| %>
<%= f.hidden_field :page, value: @pagy.next %>
<%= f.button "Load More" %>
<% end %>
<% end %>
<br>
<%= link_to 'New Email', new_email_path %>
One thing to note, our “Load More” button is actually a form. By default, forms in Rails are “remote”, meaning Rails automagically submits the form as an AJAX request. What’s more, Rails expects and will evaluate JavaScript returned by the server in response to that AJAX form submission. So loading more results happens seamlessly if we add an app/views/emails/index.js.erb file like this:
// app/views/emails/index.js.erb
document.querySelector("tbody").
insertAdjacentHTML(
'beforeend',
'<%= j render(partial: "email", collection: @emails) %>'
);
<% if @pagy.next %>
document.querySelector("input[name=page]").value = '<%= @pagy.next %>';
<% else %>
document.querySelector("form").remove();
<% end %>
That will find the emails on whatever page our form submitted, generate the HTML for that page of emails as a bunch of tr elements using our partial, and return the JavaScript needed to append those tr elements to our table and ditch the button if there’s no more pages.
Recovering pages loaded using cookies and headers
Opting to just give it away in the subtitle 😬 But if we’re not using the URL, we only have two other options: cookies and headers. We’re gonna use both.
Let’s start with a monkey patch 🙈
# config/initializers/monkey_patches.rb
module ActionDispatch
class Request
def turbolinks?
!get_header("HTTP_TURBOLINKS_REFERRER").nil?
end
def full_page_refresh?
!xhr? && !turbolinks?
end
end
end
ActionDispatch::Request ships with an xhr? method that checks the value of the X_REQUESTED_WITH header to decide if the request is an AJAX (or XMLHttp) request. Importantly, remote forms properly add this header.
We’re adding a turbolinks? method that also checks a header to decide if this is a Turbolinks-initiated request and a full_page_refresh? method.
This allows us to interrogate our request to decide what pagination action we should perform:
In Email#index and |
Then |
|---|---|
request.xhr? |
Someone clicked “Load More”, give them the JavaScript response that will append the next page of tr elements |
request.turbolinks? |
Someone is coming back to /emails, give them all the pages they’ve requested this session |
request.full_page_refresh? |
Someone clicked the refresh button, give them just page one |
For saving which pages we’ve loaded in the session, let’s first look at the API at a high-level:
class EmailsController < ApplicationController
def index
@pagy, @emails = paginates(Email.all)
end
end
class ApplicationController < ActionController::Base
include Pagy::Backend
include Pagination
end
module Pagination
extend ActiveSupport::Concern
class Paginator; end # redacted the implementation for now
included do
before_action { session.delete(:pagination) if request.full_page_refresh? }
end
def paginates(collection)
Paginator.new(self, collection).
then { |paginator| [paginator.pagy, paginator.items] }
end
end
We’ve mixed into all our controllers a concern that gives us a new paginates method. It’s a light wrapper around pagy that knows when and how to load any previously loaded pages. The return is the same as pagy – a Pagy object that holds some metadata like what the next page is, and a collection of emails.
In the concern, without the details of the Paginator class, you’ll see two things:
-
paginatesjust punts all the heavy lifting to an instance ofPaginatorthat receives the controller object and the collection -
We setup a
before_actionthat clears our session data for pagination whenever our app receives afull_page_refresh?
Before we look closer at the Paginator class, let’s look at the structure of session[:pagination]:
session[:pagination] = {
"#{controller_name}_#{action_name}" => max_page_param_seen,
# for example
"email_index" => 2
}
So it’s a single session key that we save all of our paginated resources’ max_pages in, meaning, whenever our app sees a full_page_refresh anywhere, we clear them all.
By default, the Rails session hash is backed by a cookie. We can write like this session[:pagination] ||= {} or read like this session[:pagination][key], and just remember that’s writing to and reading from a cookie.
Ok, here’s the Paginator class:
class Paginator
attr_reader :controller, :collection, :items, :pagy
delegate :request, :session, to: :controller
def initialize(controller, collection)
@controller = controller
@collection = collection
@items = []
paginate
end
private
def paginate
if load_just_the_next_page?
single_page_of_items
else
all_previously_loaded_items
end
end
def load_just_the_next_page?
request.xhr?
end
def cache_key
"#{controller.controller_name}_#{controller.action_name}"
end
def session_cache
if (caches = session[:pagination])
caches[cache_key]
end
end
def write_to_session_cache(page)
session[:pagination] ||= {}
session[:pagination][cache_key] = page
end
def max_page_loaded
[
controller.send(:pagy_get_vars, collection, {})[:page].try(:to_i),
session_cache,
1
].compact.max
end
def single_page_of_items
@pagy, @items = controller.send(:pagy, collection).
tap { write_to_session_cache(max_page_loaded) }
end
def all_previously_loaded_items
1.upto(max_page_loaded).each do |page|
controller.send(:pagy, collection, page: page).
then do |(pagy_object, results)|
@pagy = pagy_object
@items += results
end
end
end
end
That’s a lot, but really three main methods – paginate, single_page_of_items, and all_previously_loaded_items – and a bunch of helper methods.
paginate is responsible for deciding if we need just the requested page or all pages we’ve seen thus far. paginate is called in the initializer. Once initialized, you can use the Paginator#pagy method to get the most recent Pagy object and Paginator#items to get the collection of emails. items might be just a page worth emails, or it might be all of the emails we’ve seen thus far.
single_page_of_items does what you might expect, as well as making sure we update our session cookie with the max_page_loaded.
all_previously_loaded_items retrieves the max_page_loaded out of the session and makes sure we load from page one to that page.
That’s it!
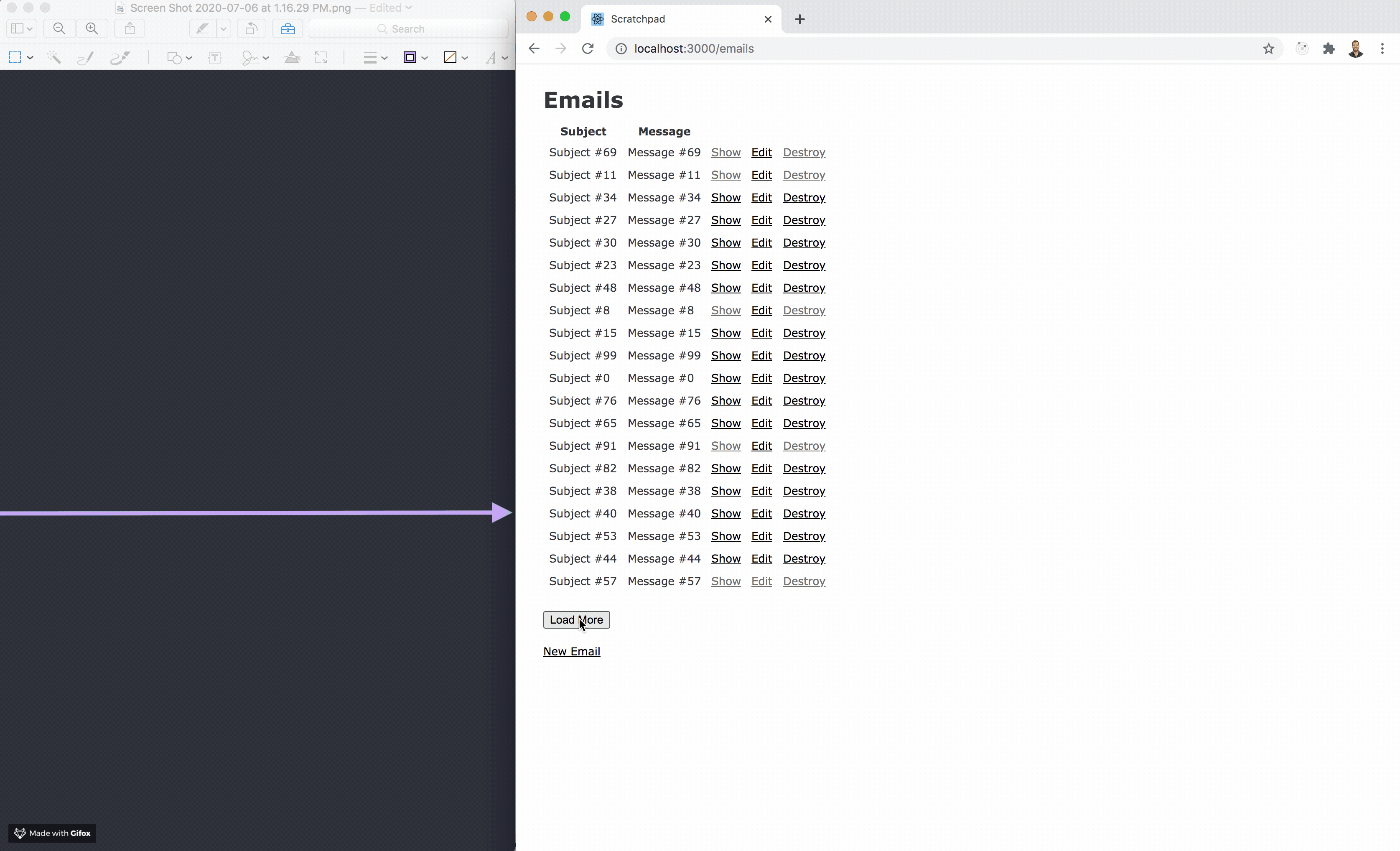
With that, it should work! 🎉 Here’s some interactions I screen grabbed:
Opening an email after loading more and coming back to the inbox
Navigating to multiple pages before coming back to the inbox
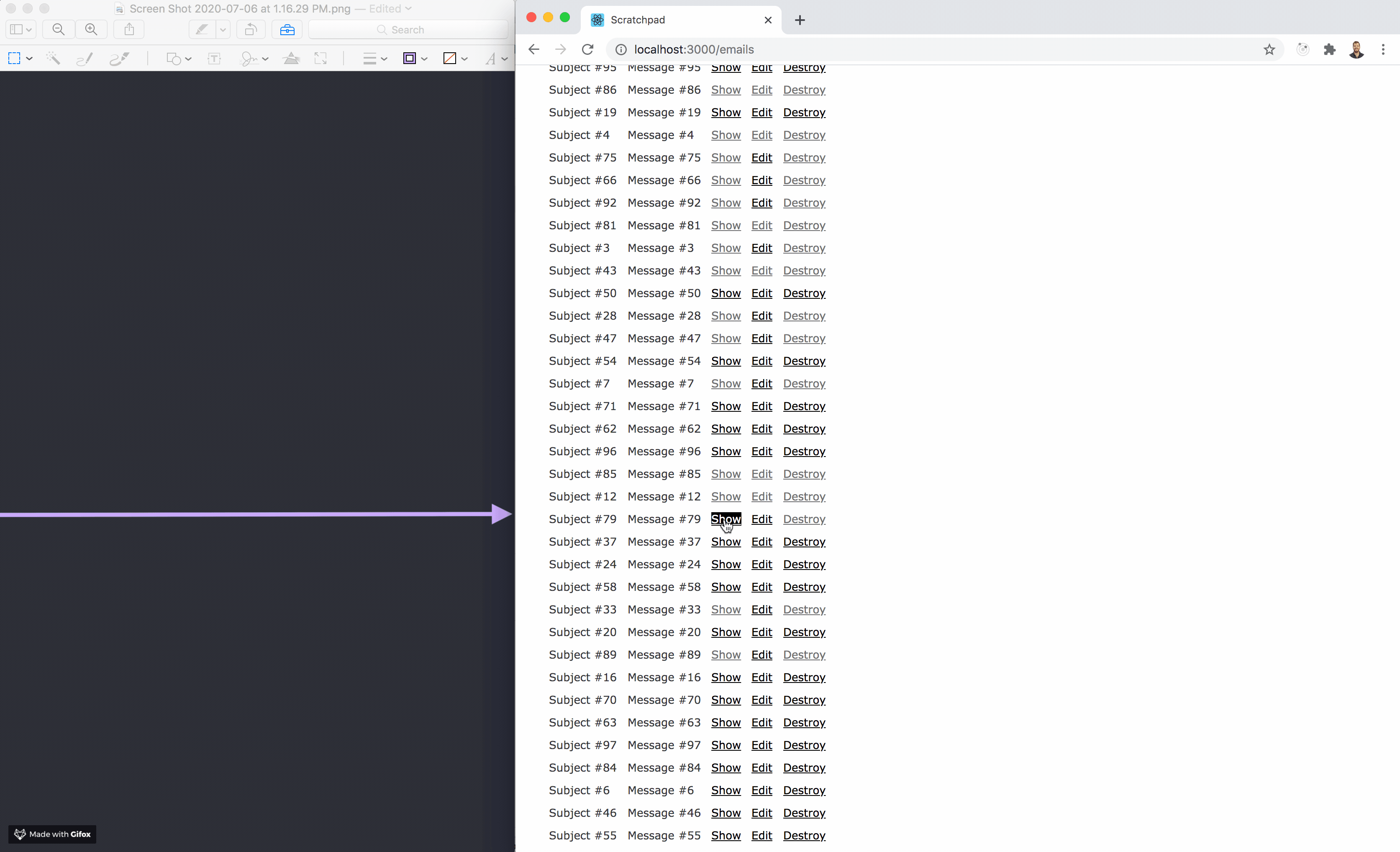
Using the back button
Triggering a page refresh before coming back to the inbox
Conclusion
Restoring pagination and scroll position: Is it difficult? Yeah, I’d say so. It at least qualifies as non-trivial.
Is it more difficult than doing the same in React? I don’t think so. The logic for “save a scroll position and restore it” is going to be virtually the same. I hear you objecting that we wouldn’t have had to store max_page_loaded in a cookie with React. Ok sure, but only because you probably took on the much larger task of keeping a cache of your database in Redux or context or local storage or whatever, for which you get zero simplicity points.
Is it impossible? Definitely not.
Code can be found here.