Pagination and Scroll Restoration with Turbolinks, but without Cookies
Well, Rich found the first post. Kinda cool 😎
But then Brian had to go and ruin the ride.
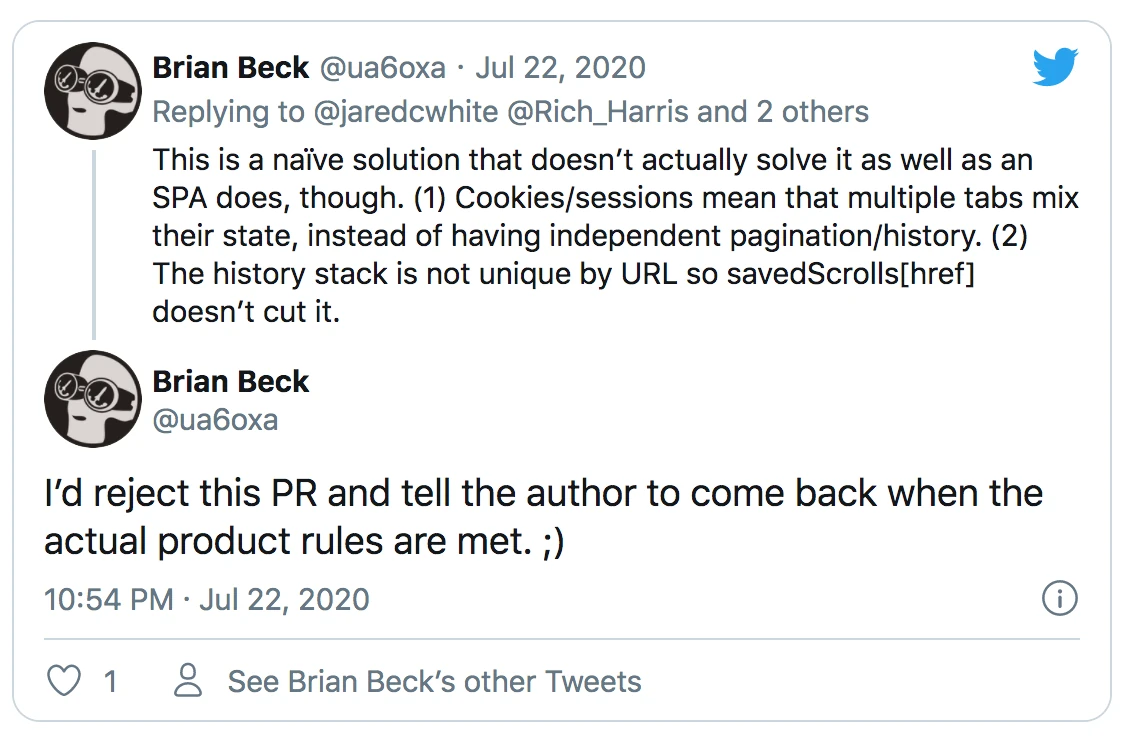
Naive, doesn’t actually solve it, PR rejection – vicious. Also, it’s my blog, mate. I’ll decide what the product rules are!
But, ugh, he has a point. Here’s pass one shitting the bed just because you opened an email in a new tab:
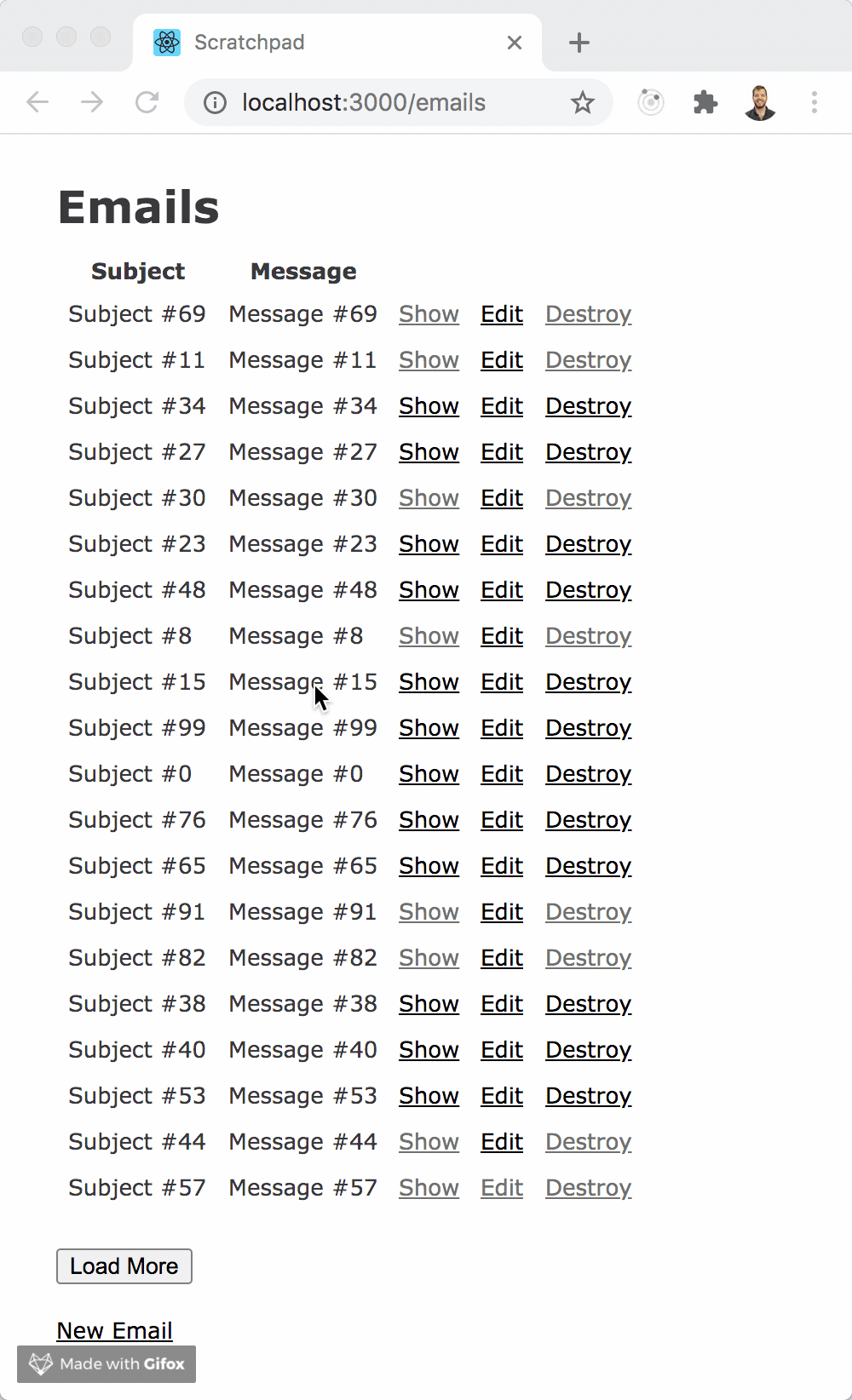
We clear the cookie when you open an email in a new tab, so then when you click “Show” and “Back” in your original tab, we forget where we were in the list. Plus, it’d be extra broken if we had two inbox tabs open – they’d overwrite each others’ last page.
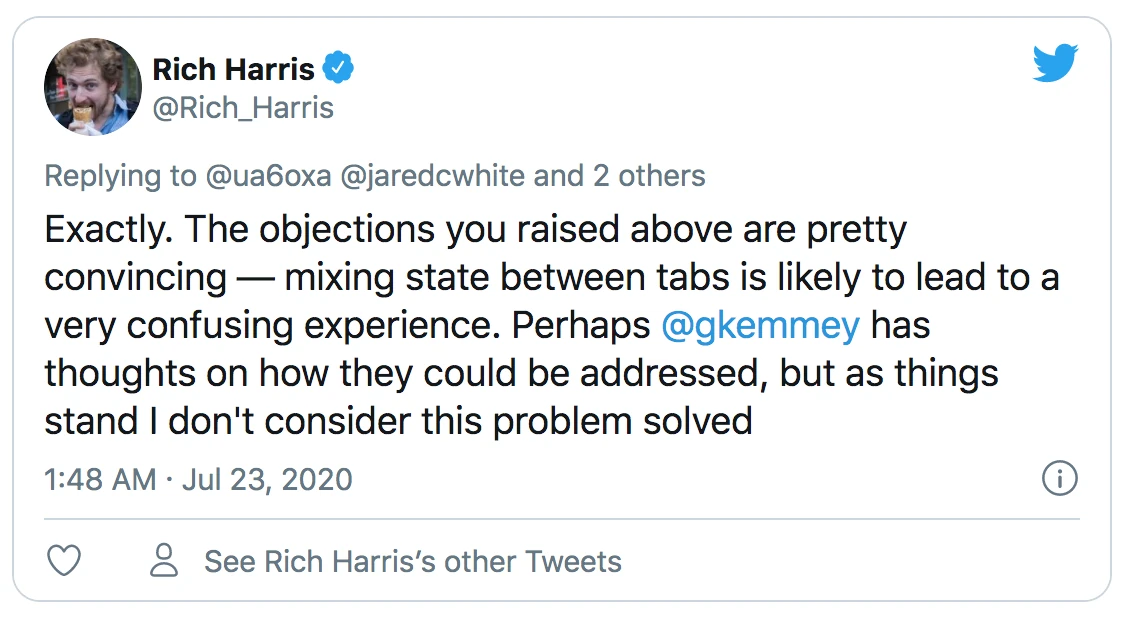
Ooofff we went from “hacky, but clever” to PRs getting rejected and “I don’t consider this problem solved”.
Fine, let’s try again.
Ok, so the first solution isn’t entirely correct. But everything down there 👇 I wrote as if you had read the first post. Heads up!
Take two, no cookies 🍪
So cookies are out. They’re the culprit here – they’re not unique per tab. So what is? Two things I can think of: the URL and sessionStorage.
In our first solution, we never changed the URL. The inbox was at /emails and as you loaded more, you stayed at /emails. That’s nice. Like I like that the URL stayed pretty. But what if we updated the URL as you loaded more?
You start at /emails. You load page two by asynchronously requesting /emails?page=2, and what if when that finished, your address bar changed to reflect it? That would mean if you load more, then click through to some other page, then click the browser’s back button, the browser would know where you were in the list – it’s in the URL. And the server wouldn’t have to know, it’s going to get a request that tells it.
Keeping the page in the url
If you remember, when we click the “Load More” button, we get some JavaScript back from the server that we want the browser to execute. In our first solution, that just appended rows to the table. We can use that same setup to update our url:
// app/views/emails/index.js.erb
(function() {
document.querySelector("tbody").
insertAdjacentHTML(
'beforeend',
'<%= j render(partial: "email", collection: @emails) %>'
);
<% if @pagy.next %>
document.querySelector("input[name=page]").value = '<%= @pagy.next %>'
<% else %>
document.querySelector("form").remove()
<% end %>
// -------- 👆old stuff, unchanged --------
// -------- 👇new stuff --------
let url = '<%= current_page_path %>'
history.replaceState(
{ turbolinks: { restorationIdentifier: '<%= SecureRandom.uuid %>' } },
'',
url
)
})();
That shouldn’t look horribly unfamiliar, it’s just history.replaceState, but with some state that keeps Turbolinks in the loop.
Handling pagination
Ok, before when it came time to paginate we made a decision server-side between “just load the page in the page param of the URL” or “load all the pages up to the one in the cookie”. Every time we loaded a new page, we also had to update the cookie. In the first solution, we had a Paginator class responsible for both deciding what to load, and persisting our max_page_loaded.
Now, it’s simpler. We only ever read from the page param. We persist nothing since it’s in the URL. We just make a decision, based on the request type, to load either just the next page or all pages up to this point. Take a look:
class EmailsController
include Pagination
def index
preserve_scroll
@pagy, @emails = paginates(Email.all.order(:predictably))
end
end
module Pagination
extend ActiveSupport::Concern
class Paginator
attr_reader :controller, :collection, :items, :pagy
delegate :request, to: :controller
def initialize(controller, collection)
@controller = controller
@collection = collection
@items = []
paginate
end
private
def paginate
if load_just_the_next_page?
single_page_of_items
else
all_previously_loaded_items
end
end
def load_just_the_next_page?
request.xhr?
end
def single_page_of_items
@pagy, @items = controller.send(:pagy, collection)
end
def all_previously_loaded_items
1.upto(page_to_restore_to).each do |page|
controller.send(:pagy, collection, page: page).
then do |(pagy_object, results)|
@pagy = pagy_object
@items += results
end
end
end
def page_to_restore_to
[
controller.send(:pagy_get_vars, collection, {})[:page].try(:to_i),
1
].compact.max
end
end
def paginates(collection)
Paginator.new(self, collection).
then { |paginator| [paginator.pagy, paginator.items] }
end
end
With that, we can load more, our URL updates, and we can restore scroll when you click the browser’s back button:
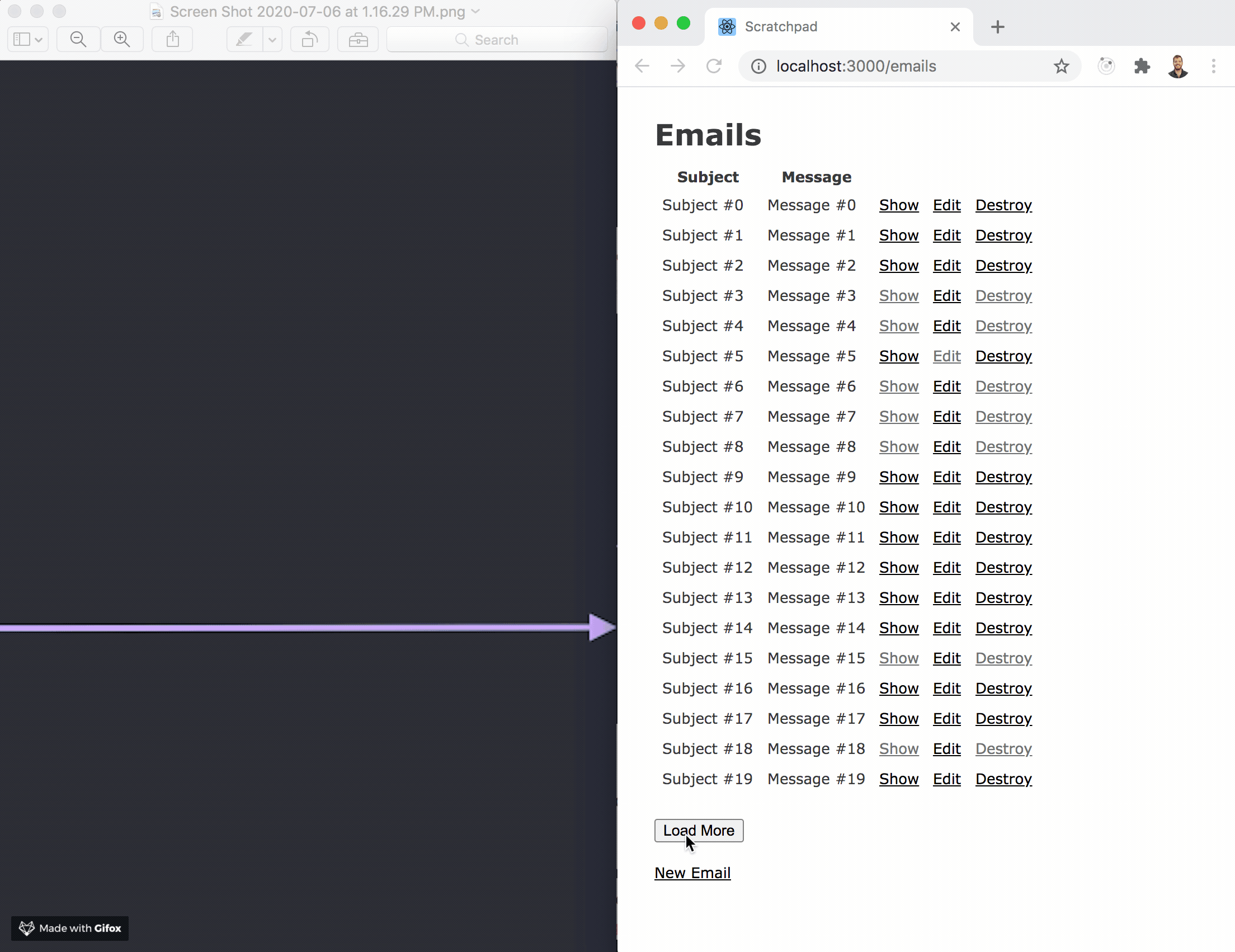
Refreshing should…well…start fresh
At this point, we’ve lost something we had in the old version: if you refresh your inbox we should forget pagination and scroll, and start back at the top. Now that we’re tracking pagination state in the URL, when you click refresh, you get results up to that page.
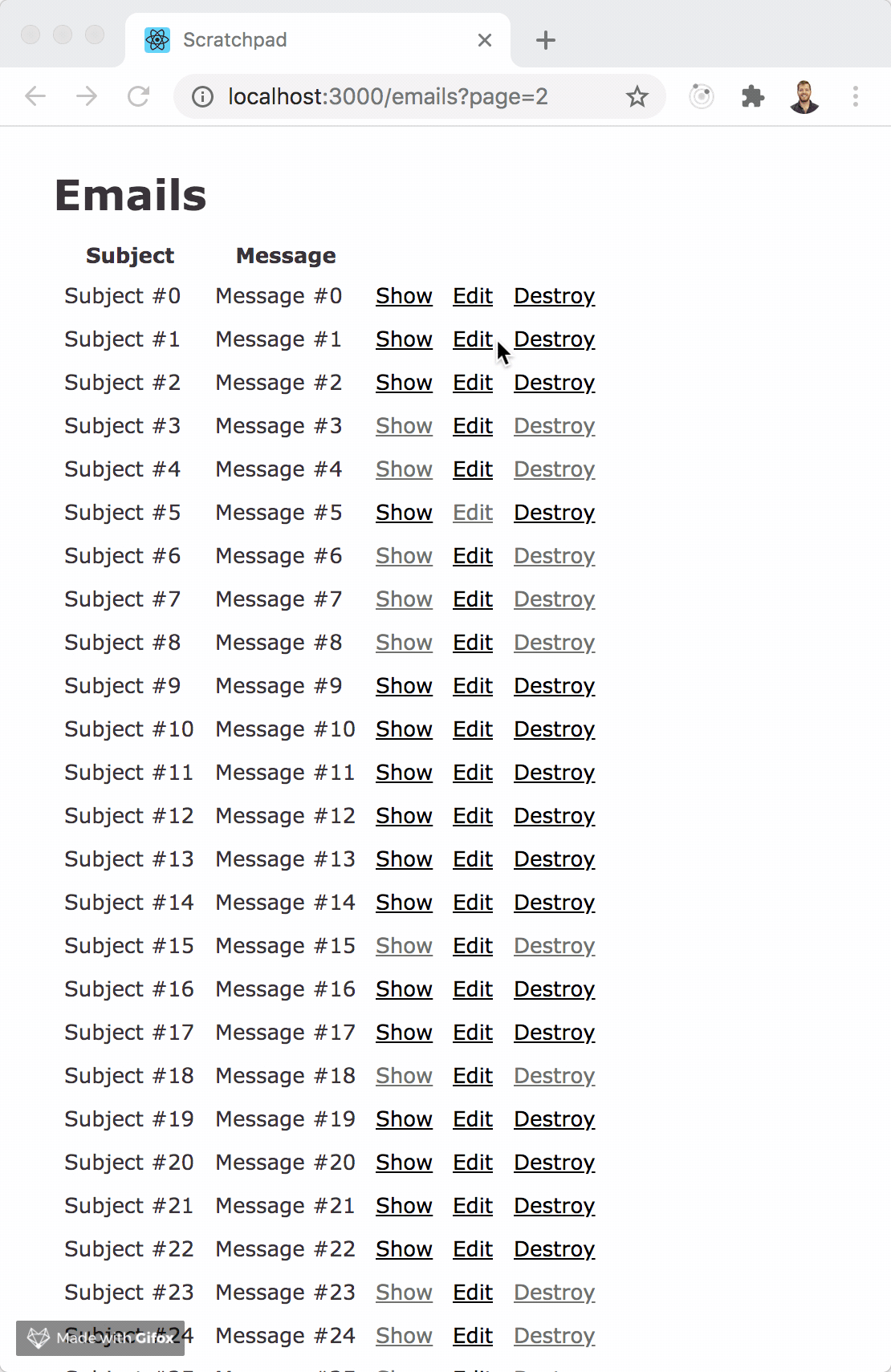
So how can we detect a user refreshing? Let’s monkey patch again 🐵
# config/initializers/monkey_patches.rb
module ActionDispatch
class Request
def full_page_refresh?
get_header("HTTP_CACHE_CONTROL") == "max-age=0" ||
(
user_agent.include?("Safari") &&
get_header("HTTP_TURBOLINKS_REFERRER").nil? &&
(referrer.nil? || referrer == url)
)
end
end
end
For Chrome and Firefox, when you refresh or navigate directly to a url they both set a Cache-Control header to max-age=0. So if we see that, we can treat this request as a full_page_refresh?. Safari however does not set that header. So if it looks like it’s Safari we’re dealing with we uh…guestimate. Our “Safari’s refreshing” guestimate is 1) there’s no Turbolinks referrer i.e. we didn’t get here form a Turbolink and 2) the browser’s referrer is either not set or set to this page you’re requesting.
There’s probably room for improvement here 😬 But armed with that helper method, we can make a server-side decision to ignore any page params set in a user’s request. Here’s what that looks like:
module Pagination
extend ActiveSupport::Concern
# ... Paginator class and paginates methods ...
def fresh_unpaginated_listing
url_for(only_path: true)
end
def redirecting_to_fresh_unpaginated_listing?
if request.full_page_refresh? && params[:page]
redirect_to fresh_unpaginated_listing
return true
end
false
end
end
class EmailsController < ApplicationController
def index
preserve_scroll
return if redirecting_to_fresh_unpaginated_listing?
@pagy, @emails = paginates(Email.all.order(:predictably))
end
end
Now when we refresh the page – even if we’re at a URL like /emails?page=2 – or navigate to it directly, the server can instead give us the fresh, unpaginated list of emails:
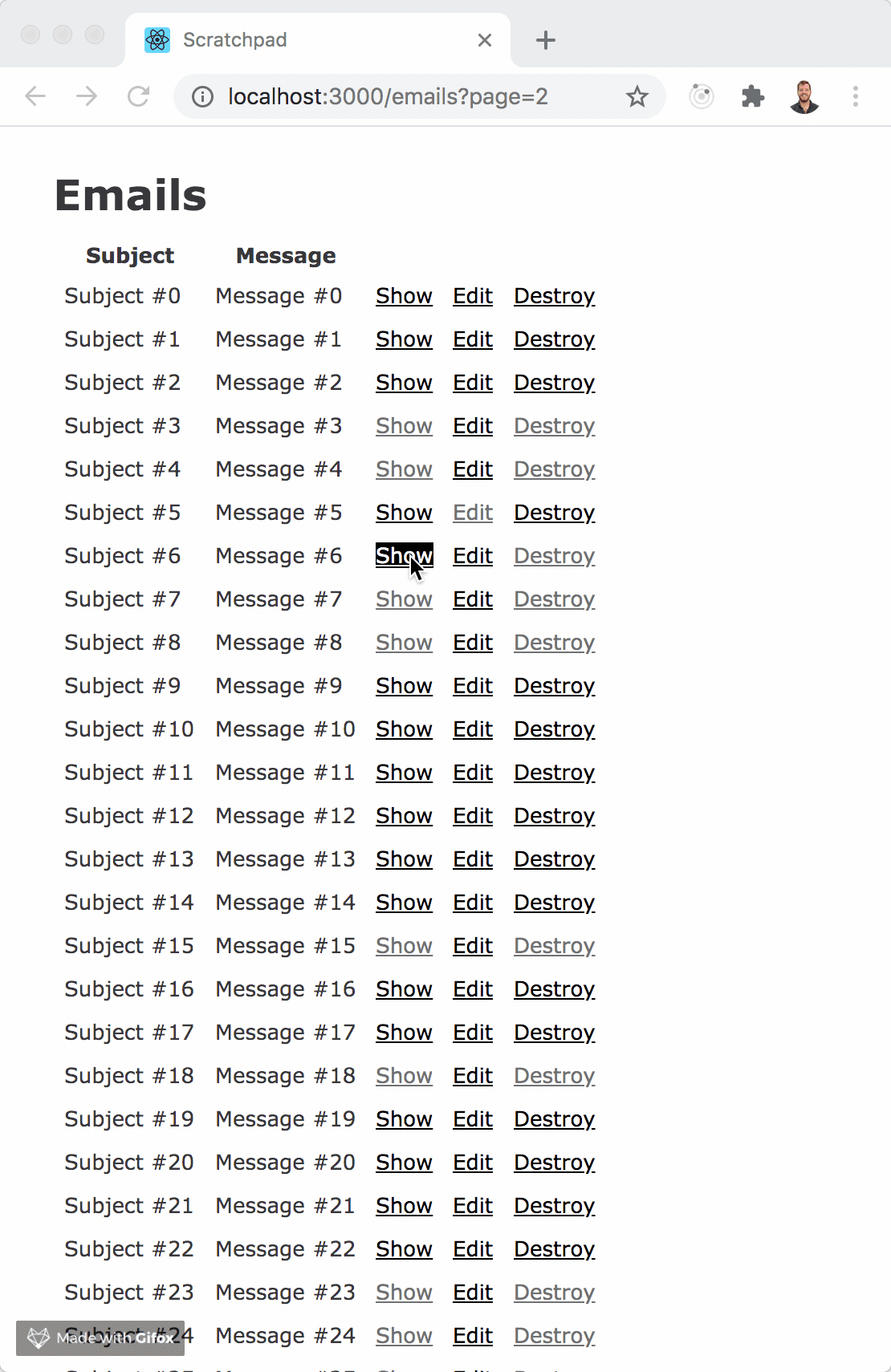
Our app’s links should work
So far, we have pagination and scroll restoration working with the browser’s back button – what about our “Back” links. Our app has them both on the show page and on the edit page. In our original version, you could even go from inbox -> show -> edit -> click "Back", and have the inbox recover your scroll and pagination. It’d be nice if that continues to work.
Here’s where sessionStorage comes in. Every time we load more emails, we update our URL to where in the list we are. Let’s also drop a little note in sessionStorage. That way as we click into our application we can remember what our URL was.
First, let’s add some helpers to that Pagination concern:
module Pagination
extend ActiveSupport::Concern
def clear_session_storage_when_fresh_unpaginated_listing_loaded
script = <<~JS
sessionStorage.removeItem('#{last_page_fetched_key}');
JS
helpers.content_tag(:script, script.html_safe, type: "text/javascript",
data: { turbolinks_eval: "false" })
end
def current_page_path
request.fullpath
end
def last_page_fetched_key
"#{controller_name}_index"
end
included do
# 👇 rails for "let me use this method in the controller and the view"
helper_method :clear_session_storage_when_fresh_unpaginated_listing_loaded,
:current_page_path,
:last_page_fetched_key
end
end
Next, let’s adjust that JavaScript response where we update the URL to also update sessionStorage:
// app/views/emails/index.js.erb
(function() {
// ... adding table rows ....
let url = '<%= current_page_path %>'
// ... updating the address bar and turbolinks ...
sessionStorage.setItem('<%= last_page_fetched_key %>', url)
})();
Cool, now we’re updating both the URL and sessionStorage. We just wrote some code for clearing the URL when you refresh, now we need to clear sessionStorage, too.
Refreshing the URL serves our index.html.erb view, so we can do it there:
<!-- app/views/index.html.erb -->
<!-- ... header ... -->
<!-- ... table ... -->
<!-- ... load more ... -->
<%= clear_session_storage_when_fresh_unpaginated_listing_loaded %>
clear_session_storage_when_fresh_unpaginated_listing_loaded renders a script tag that has the actual JavaScript for clearing sessionStorage, and it decorates that script tag with some data attributes that tells Turbolinks “look if you ever load this page from a cache, don’t run that script again”. So it’s just our response to the user’s refresh that’ll run that script and clear the sessionStorge key.
Ok, so we’ve got the current pagination url in sessionStorage; we clear it out when our URL resets – now we’ve gotta use it when our links are clicked.
First, we decorate our links in app/views/emails/show.html.erb and app/views/emails/edit.html.erb like so:
<%= link_to 'Back', emails_path,
data: { restores_last_page_fetched: last_page_fetched_key } %>
Second, we need just a little more JavaScript to make that work. Turns out when a link is clicked, we’ll see that click event before Turbolinks takes over. So we can listen for clicks on decorated links and tell Turbolinks where to go:
on(document, "click", "a[data-restores-last-page-fetched]", function(event) {
const { target: a } = event
const { restoresLastPageFetched: key } = a.dataset
const lastPageFetched = sessionStorage.getItem(key)
if (lastPageFetched) {
a.href = lastPageFetched
}
})
So, when a <a data-restores-last-page-fetched="key"> link is clicked, we grab that key, see if there’s a value in sessionStorage for it, and if so swap out the href attribute before Turbolinks starts its thing. Check it out:
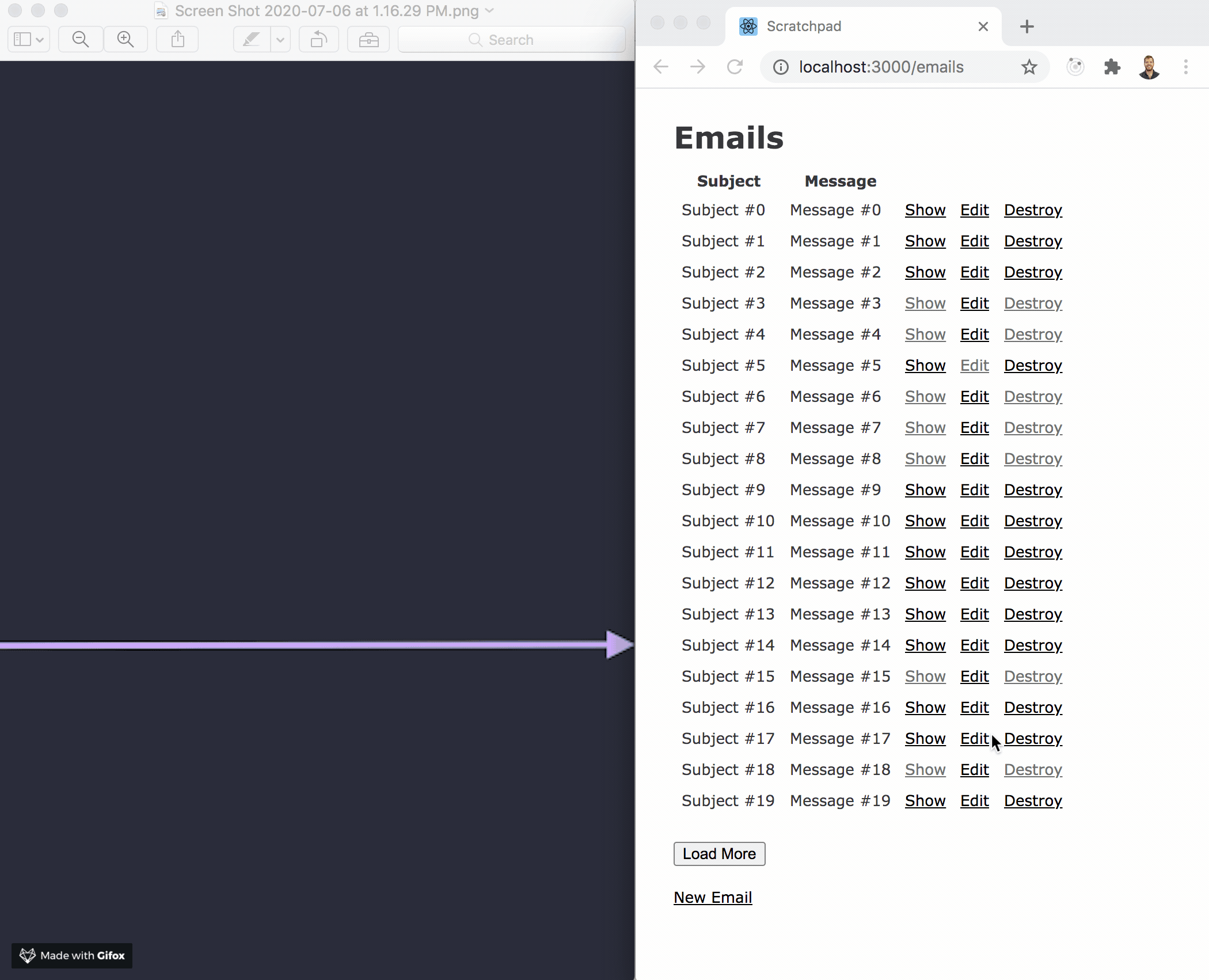
What about multiple tabs? Isn’t that why we’re here?
Right you are!
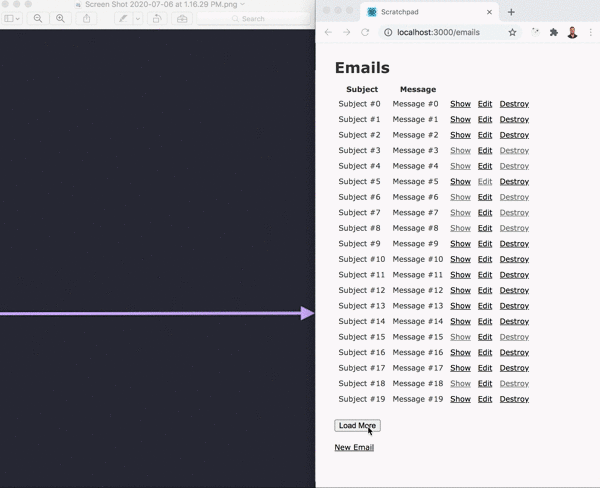
What about the history stack is not unique by URL so you can’t save scroll positions by URL?
Turbolinks is (mostly) bailing us out here. Turbolinks saves the scroll position before navigating away and restores that position when it loads the page from cache – i.e. you click the browser’s back button.
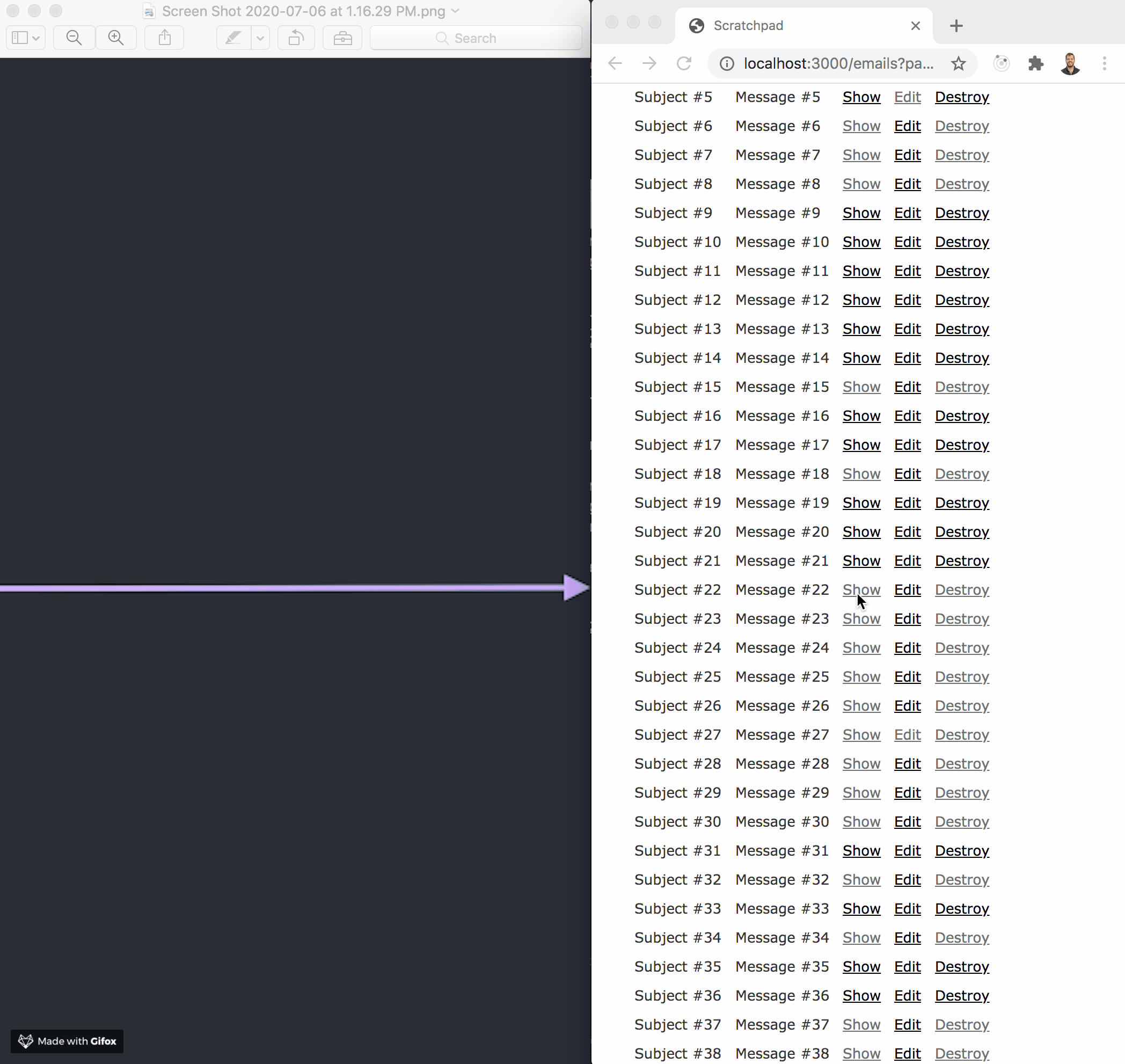
We scroll to #22, open it, click “Back”, scroll to #44, and open it. Now, we click the back button, we get that cached page scrolled to #44. Click the back button twice more, we get that other cached page scrolled to #22.
I’m not sure scroll is always restored if you mix using the browser’s back button and our app’s back link. That said, if Turbolinks has a scroll position and we don’t, surely we could go get it. Alternatively, we could change our savedScrolls object. What if it was a stack per URL? Then to restore scroll, we pop the last value we had for that URL (rather than the only value we have for that URL).
Anyway, I think that’s everything. Opening it for re-review, anyway.
Conclusion
Restoring pagination and scroll position: I guess it’s more difficult than I thought. I definitely didn’t think about multiple tabs. There might even be edge cases I’m still not thinking about, but at this point, we’re well past “it’s impossible with Rails and Turbolinks”.
So, I think it’s y’all’s turn. Let’s see that Sapper / Svelte, Next.js / React, SPA goodness.
Code can be found here.
Bonus
If scroll restoration and pagination is gonna become my thing, I wrote some tests for it. You can see the test cases – all the def test_x methods – here. It’s kinda readable even without Ruby / Rails experience. Let me know if I’m missing any!
Also, it’s an impressive display of browser testing capabilities you get out-of-the-box with Rails. People forget the allure of Rails is so much more than just server-rendering. It’s a vast tool set that makes everything so. god. damn. enjoyable.
Chrome
Safari